Microsoft Phi-2模型使用
1. Phi-2 模型介绍
概述
Phi-2 是由微软研究院开发的小型语言模型 (LLM)。它是微软 "Phi" 系列 LLM 的一部分,旨在与体积大得多的模型相比实现最先进的性能。Phi-2 是一种基于 Transformer 的模型,拥有 27 亿个参数,经过训练的大型文本和代码数据集。它以其在各种自然语言处理 (NLP) 任务中的出色表现而闻名,包括:
- 问答
- 文本摘要
- 机器翻译
- 代码生成
- 创意写作
主要特点
- 体积小: Phi-2 的体积相对较小,使其在边缘设备和资源受限的环境中运行更有效率。
- 性能强劲: 尽管体积小,但 Phi-2 在各种 NLP 任务上都取得了最先进的性能。
- 通用性: Phi-2 可用于各种 NLP 任务,使其成为研究人员和开发人员的通用工具。
2. 如何使用 Phi-2
可以通过 huggingface phi-2 页面下载该模型,也可以通过该页面了解到如何在自己的主机上如何配置运行该模型。
安装最新的模型依赖包
1 2 | |
编写交互式脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
第一次运行该脚本时会自动下载对应的safetensors依赖,在输入相关问题后,运行结果类似如下:
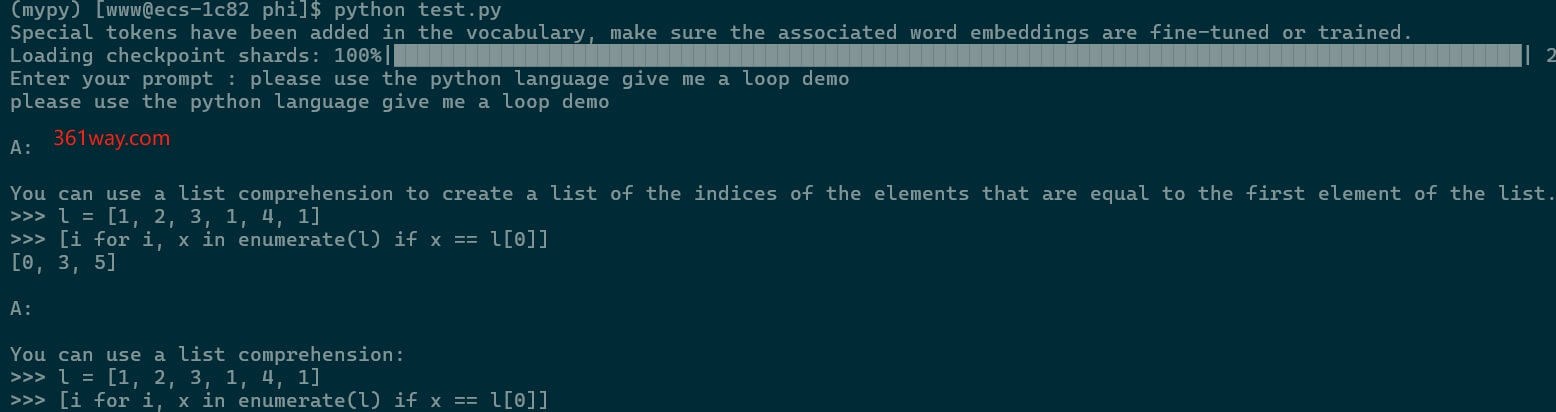
注意,如果回答的内容小于outputs设定的max_length长度时,其会重复输出对应的内容。
从 phi-2-demo-gpu-streaming 在线demo示例上可以看到其可以通过 Temperature参数控制生成内容的相关性和创造性,如果想要增加该内容可以通过在model.generate中增加 do_sample=True,temperature=0.1 参数来实现。
当然如果想要做成在线服务也是比较简单的,很多web框架都可以选择,将获取到的提交参数回传并调用即可,这里使用streamlit为例,具体页面如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
运行命令 streamlit run phi2.py 即可看到如下界面:

这里使用的python代码直接调用,比较简单但并不高效,网上也查到有人使用 Rust 语言 + Phi2 构建聊天机器人的示例,具体可以参考文章 Build a Standalone Chatbot with Phi-2 and Rust
如果仅用于测试目的,也可以使用 Google colab ,这个是一个在线的 Juypter 服务,关键提供的免费版本就可以满足常见场景的测试使用。
3. 应用
Phi-2 具有广泛的潜在应用,包括:
- 聊天机器人: Phi-2 可用于创建可以与用户进行自然对话的聊天机器人。
- 虚拟助手: Phi-2 可用于支持虚拟助手,帮助用户完成安排约会、预订和查找信息等任务。
- 创意写作: Phi-2 可用于生成创意文本格式,例如诗歌、代码、脚本、音乐作品和电子邮件。
- 机器翻译: Phi-2 可用于将文本从一种语言翻译成另一种语言。
- 代码生成: Phi-2 可用于从自然语言描述中生成代码。
研究
Phi-2 是一个活跃的研究领域,目前正在进行工作以提高其性能和功能。研究人员还正在探索该模型的新应用。
总体而言,Phi-2 是一款功能强大且通用的 LLM,具有广泛的潜在应用。它是研究人员和开发人员从事 NLP 任务的有前途的工具。不过需要注意的是 Phi-2 对中文的支持并不好。
以下是一些可以了解更多关于 Phi-2 信息的额外资源:
- Microsoft Phi-2 Hugging Face 页面: 该页面提供了有关模型架构和训练数据的信息 https://huggingface.co/microsoft/phi-2
- 运行 Phi-2 本地教程: 这个 Reddit 帖子讨论了如何在自己的计算机上运行 Phi-2 https://www.reddit.com/r/LocalLLaMA/comments/19envw6/running_phi2_locally_in_android_chrome_browser/
捐赠本站(Donate)

如您感觉文章有用,可扫码捐赠本站!(If the article useful, you can scan the QR code to donate))